-

ORCA Hands-on Workshop
Read more: ORCA Hands-on WorkshopNational Competence Centres for HPC in Slovakia and Poland are collaborating to organize a 2-day workshop on ORCA program package. ORCA.
-

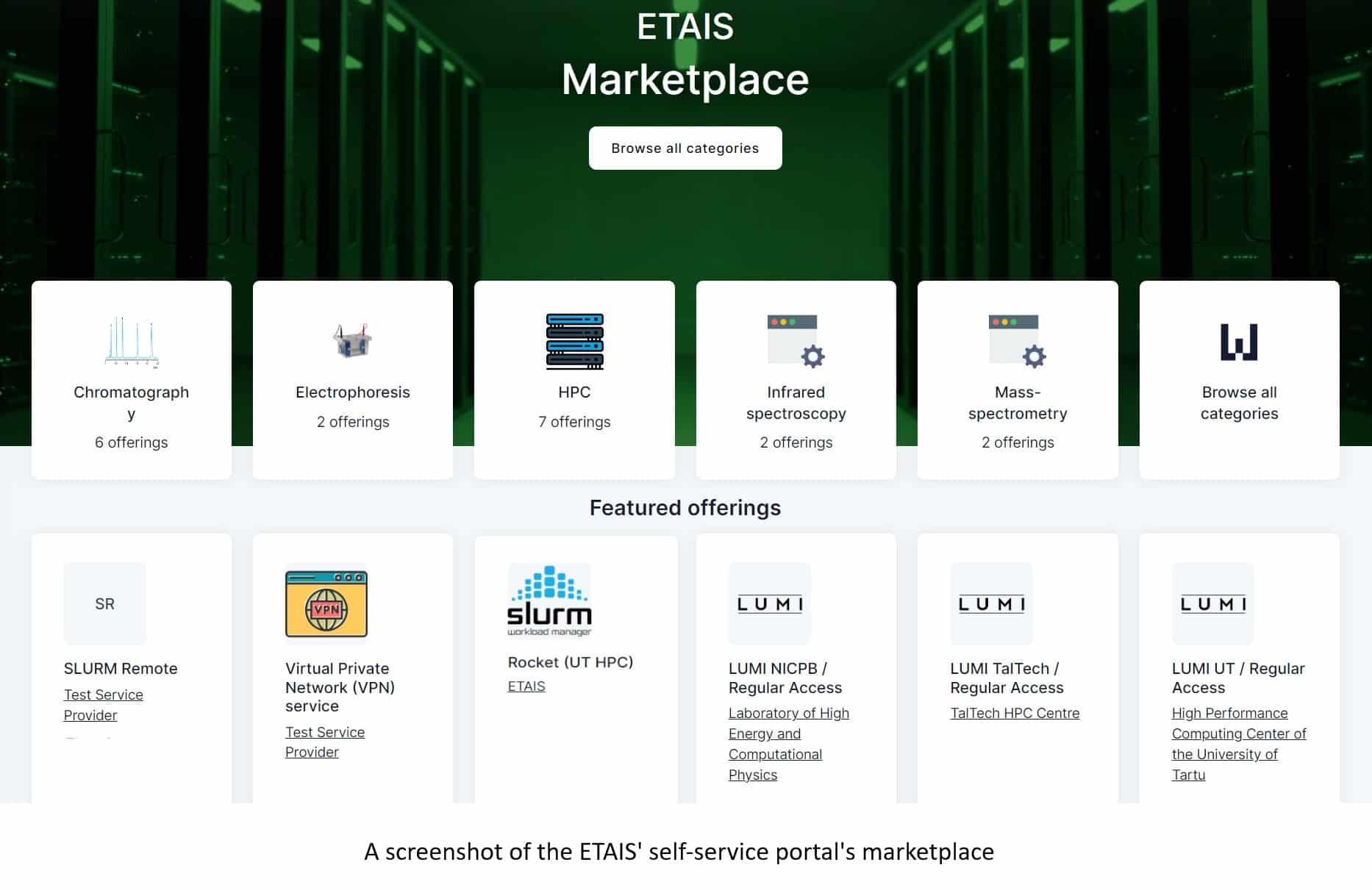
A user-friendly self-service portal encourages greater adoption of HPC
Read more: A user-friendly self-service portal encourages greater adoption of HPCProviding users with a user-friendly self-service portal empowers them to take control of their HPC usage and workflow. They can independently access resources, submit job requests, monitor job status, and […]
-

Workshop: CFD on HPC – OpenFOAM case (May 27 – 29, 2024 via Zoom)
Read more: Workshop: CFD on HPC – OpenFOAM case (May 27 – 29, 2024 via Zoom)The three-day workshop organised by NCC Slovenia and its partner, Faculty of Mechanical Engineering, University of Ljubljana, is aimed at researchers, engineers, students and others interested in CFD on HPC […]
-

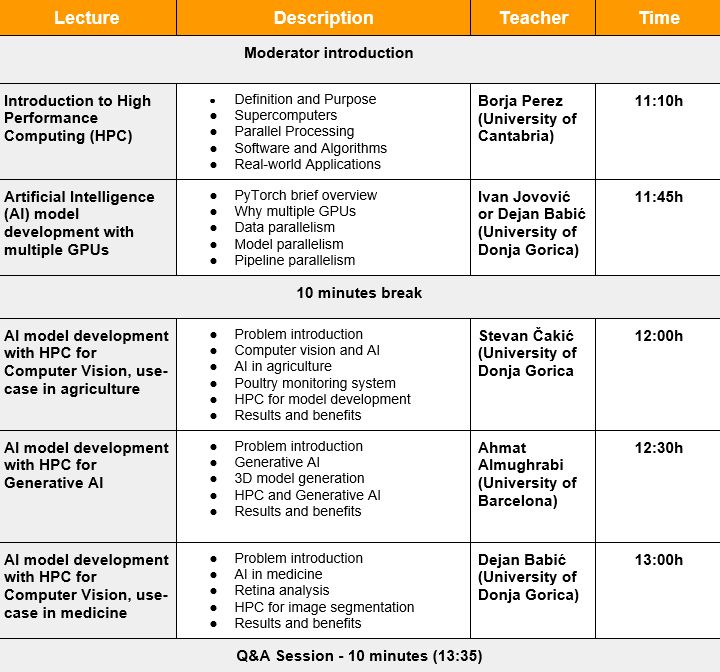
Montenegro hosted a successful cross-NCC workshop focusing on HPC/AI industry applications
Read more: Montenegro hosted a successful cross-NCC workshop focusing on HPC/AI industry applicationsDuring 28th international IT IEEE conference in Zabljak, Montenegro, the EuroCC2 HPC/HPDA/AI Workshop gathered together presenters from 6 NCCs and 5 companies providing a brief overview on more than 20 […]
-

Registration to the 4th Baltic HPC and Cloud Conference is now open
Read more: Registration to the 4th Baltic HPC and Cloud Conference is now openWe invite research communities that use HPC, including students, HPC experts, industry representatives, as well as governmental representatives to attend the 4th Baltic HPC and Cloud Conference that will take […]
-

HPC opportunities for financial industry services
Read more: HPC opportunities for financial industry servicesRepresentative of NCC Montenegro, Sanja Nikolic participated in the Round Table “Montenegrin Finance and Internationalization”, organized by Montenegrin Academy of Science and Art. On this event, topics related to the […]
-

Supercomputing info day – HPC success stories from five NCCs
Read more: Supercomputing info day – HPC success stories from five NCCsNCC Spain, NCC Netherlands, NCC Slovenia, NCC Cyprus and NCC Montenegro organized collaborative” Supercomputing INFO DAY” where companies from different industries shared their experience on using HPC infrastructure which improved […]
-

HPC and AI Workshop
Read more: HPC and AI WorkshopNCC Montenegro and NCC Spain organized the “HPC and AI Workshop” designed for academia, scholars, researchers who are interested in learning how to use Artificial Intelligence and High-performance Computing in […]
-

EuroCC Workshop HPC and Industry Application at IT2024
Read more: EuroCC Workshop HPC and Industry Application at IT2024Registration is open for the upcoming EuroCC Training Event – High Performance Computing and Industry Applications. This event is organized in alignment with the 28th International Information Technology IEEE Conference […]
Belgium