Success Story: Optimizing industrial particle processes through simulation
NCC presenting the success story
EuroCC Belgium is Belgium’s National Competence Centre (NCC) in the area of high-performance computing (HPC) and high-performance data analytics (HPDA) and coordinates activities in all HPC-related fields and serves as a reference contact point on HPC/HPDA/AI at a national level.
EuroCC Belgium is a consortium consisting of the following partners: Cenaero, CECI, Innoviris Brussel en het Vlaams Computer Centrum.



Industrial Organizations Involved:
The simulation software Mpacts can simulate the behaviour of a large number of particles through machines enabling the improvement of the machine by testing designs in a software environment before actually having to build a physical machine. This way is much more time-efficient and cost-reducing. Mpacts uses the Discrete Element Method (DEM) to understand, predict and solve industrial problems. To simulate a lot of particles, a lot of computational resources are needed. To perform simulations for clients the organization uses the VSC infrastructure.




Technical/scientific Challenge:
More particles can only be simulated in shorter time spans by making use of the parallel resources available. For ‘shared memory’ parallelism such as TBB or GP-GPU, the bottleneck for this type of simulation is typically memory bandwidth and memory latency. When switching to an MPI parallel acceleration, across multiple compute nodes, the main challenge becomes an efficient dynamic domain decomposition as the particles move across the simulated domain.
Business Impact/Benefits:
Simon Vanmarcke (Mpacts): “Using the supercomputing infrastructure of the VSC matches our usage pattern very well. Typically, we require ‘bursts’ of computational power when performing simulations for clients. It would be unfeasible and inefficient to purchase the required computational power in-house as it would be costly to do so and idle most of the time. Working with the VSC enables us to deliver results with ‘industrial turnaround times’ at a cost that scales only with how much actual simulation work is done, not with the peak resources used. A real game-changer.”
Solution:
To make the simulations faster, several paths can be taken. First, the software itself can be made more efficient and thus faster. Second, more computational resources can be used, and acceleration hardware such as GPUs can be used.
Simon Vanmarcke (Mpacts): “As a striking example of the first strategy, the experts at VSC recommended we sort the particles so that particles close in (simulated) space are also close together in computer memory. This increases the likelihood for cache hits and decreases the overall memory bandwidth.”
The effect on the computational time is illustrated in the YouTube movie for single-core performance. In GPU-accelerated simulations, the effect is much more pronounced as the memory throughput on these devices is even more of a bottleneck.
More particles can only be simulated in shorter time spans by using the parallel resources available. For ‘shared memory’ parallelism such as TBB or GP-GPU, the bottleneck for this type of simulation is typically memory bandwidth and memory latency. When switching to an MPI parallel acceleration across multiple compute nodes, the main challenge becomes an efficient dynamic domain decomposition as the particles move across the simulated domain. Additionally, the VSC makes it possible for Mpacts to obtain very large amounts of computational power which have GPU acceleration available.
SUCCESS STORY # HIGHLIGHTS:
- DEM, particle simulations, hpc
- Industry sector: services & software providers, manufacturing & engineering
- Technology: (HPC)
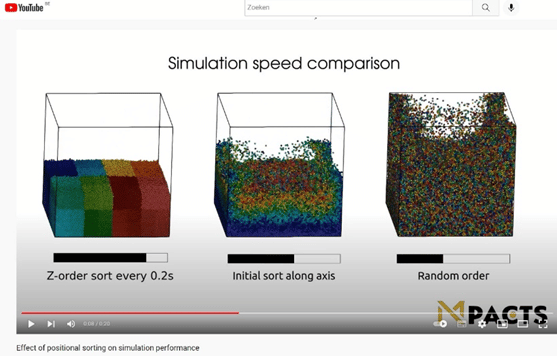
Youtube video “Effect of positional sorting on simulation performance”: https://www.youtube.com/watch?v=QPuAXO-iXOI
In this demo, a simulation is 3 times run to show the effect of memory locality on simulation speed. On the left. the particles are periodically sorted using an Z-order sort algorithm. This causes particles that are close together in ‘simulation space’ to be close together in memory too. In the middle the particles are sorted along the vertical axis. This is less optimal compared to the Z-order sorting, but still performs significantly better with respect to completely random memory locations shown on the right. The timing differences are for single-threaded CPU calculations. For GP-GPU this effect is even more pronounced due to the memory architecture
Contact:
EuroCC Belgium
Jothi Blontrock
Copywriter
W: www.enccb.be
E: communication@enccb.be or Jothi.blontrock@uhasselt.be
T: +32 11 26 86 33
L: E123 – UHasselt Campus Diepenbeek
Twitter: @EuroCC_Belgium
LinkedIn: EuroCC@Belgium
This project has received funding from the European High-Performance Computing Joint Undertaking (JU) under grant agreement No 951732. The JU receives support from the European Union’s Horizon 2020 research and innovation program and Germany, Bulgaria, Austria, Croatia, Cyprus, the Czech Republic, Denmark, Estonia, Finland, Greece, Hungary, Ireland, Italy, Lithuania, Latvia, Poland, Portugal, Romania, Slovenia, Spain, Sweden, the United Kingdom, France, the Netherlands, Belgium, Luxembourg, Slovakia, Norway, Switzerland, Turkey, Republic of North Macedonia, Iceland, Montenegro