Success Story: Fast generation of low-discrepancy sequences using accelerators
NCC-BULGARIA

The National Competence Centre of Bulgaria (NCC-Bulgaria) in the area of High-Performance Computing (HPC), High-Performance Data Analytics (HPDA) and Artificial Intelligence (AI) has the goal to enhance and develop the competences of the Bulgarian computational community, making full use of EuroHPC resources and the EuroCC partnership.
The NCC-Bulgaria is built by a consortium coordinated by the Institute of Information and Communication Technologies at the Bulgarian Academy of Sciences (IICT-BAS), and two members, Sofia University “St. Kliment Ohridski” (SU), and University of National and World Economy (UNWE). The three partners carry diverse technical and scientific background in the area of HPC and ICT in general, so as to ensure achievement of the project objectives and guarantee the overall success.
The partners collaborate with Sofia Tech Park, where the Discoverer EuroHPC supercomputer is operating.
Technical/scientific Challenge:
Computational accelerators offer significant advantages in terms of computational power when compared with regular CPUs. However, when dealing with the problem of fast generation of low-discrepancy sequences using accelerators, one has to take into account that any complex logic operations and branches in the code require significant rewriting of the code and may become a bottleneck in a quasi-Monte Carlo simulation algorithm. Such algorithms are used in problems with hundreds and frequently thousands of dimensions, arising from pricing problems in Mathematical Finance.
Scientific impact:
Various families of low-discrepancy sequences are studied and used in diverse quasi-Monte Carlo methods. Our codes dealt with the Sobol and Halton sequences, which are one of the most popular families in use. The ability to generate terms of these sequences on systems with accelerators remove a possible bottleneck in many practical applications, e.g., in Mathematical Physics and Finance. In addition to that, the reduced computational cost of generation enabled various efforts for optimising the parameters of these sequences and their distribution properties. Such optimisation procedures employ heuristic optimisation techniques in a setting with very high number of parameters (thousands). The results from the optimisations are stored and can now be used in solving complex practical problems.
Partners involved in the success story:

The department of Scalable Computing and Applications (SCA) with HPC Centre is one of the departments of the Institute of Information and Communication Technologies at the Bulgarian Academy of Sciences (IICT-BAS). It manages the HPC centre where is located the supercomputer Avitohol.
The department SCA with HPC centre is focused on activities in the development and deployment of Cloud middleware and software components, methods, algorithms, and applications suitable for Cloud and HPC computing systems. All researchers in the Department were involved/are involved in the pan-European and regional projects for building Open Science cloud or HPC infrastructures in FP7 and Horizon 2020 for different research communities.
Solution:
Modern compilers have powerful built-in vectorisation and optimisation techniques that allow good speed-up to be achieved for codes that have suitable patterns of executing loops and memory accesses. When dealing with our problem, we divided the codes into two parts. For those parts where we expected that the compilers can do better job at vectorisation/optimisation, we added suitable labels at critical points in the code, where some compiler directives or parameters can be varied, and then we considered the performance of the code on certain representative test cases as a loss function that is to be optimised. The optimisation problem is high-dimensional, with mostly integer variables. For finding the optimum we employed a genetic algorithm and we obtained acceptable performance. Interestingly, in some places it was better to disable the vectorisation capabilities of the compiler for best results.
In order parts of the code, we reorganized the logic operations in a way that decreases branching or at least groups together threads with similar branching patterns. In some cases branching was replaces with a combination of logic and arithmetic operations that achieves the same overall result. Optimising this second part was more time-consuming but achieved much better improvement in execution speed.
Benefits:
- Fast generation of low-discrepancy sequences enables the use of quasi-Monte Carlo methods on supercomputers equipped with accelerators, with their superior accuracy in complex, high-dimensional problems.
- Leveraging compiler’s ability to optimise and vectorise saves development time and decreases code complexity.
- Decreasing the computational cost of the generation process enables other algorithms and techniques that otherwise were unfeasible.
SUCCESS STORY # HIGHLIGHTS:
- Keywords: Supercomputer applications; High-dimensional simulations
- Industry sector: Finance
- Technology: HPC, AI
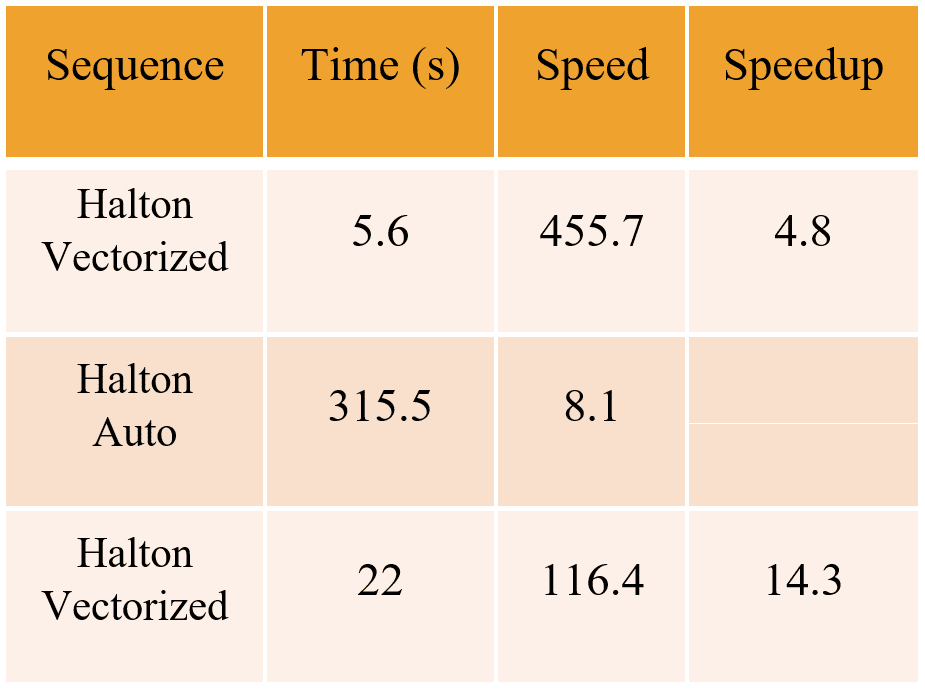
Comparison of speeds of generation in millions of coordinates per seconds, 10 million points in 256 dimensions:
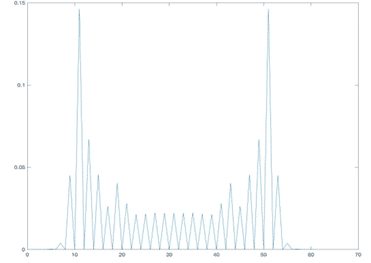
Discrete probabilities for a 30-step quantum walk, used in QMC simulations
Contact:
Prof. Emanouil Atanassov,
Prof. Aneta Karaivanova,
Assoc. Prof. Sofiya Ivanovska
Mariya Durchova
Institute of Information and Communication Technologies,
Bulgarian Academy of Sciences
This project has received funding from the European High-Performance Computing Joint Undertaking (JU) under grant agreement No 951732. The JU receives support from the European Union’s Horizon 2020 research and innovation program and Germany, Bulgaria, Austria, Croatia, Cyprus, the Czech Republic, Denmark, Estonia, Finland, Greece, Hungary, Ireland, Italy, Lithuania, Latvia, Poland, Portugal, Romania, Slovenia, Spain, Sweden, the United Kingdom, France, the Netherlands, Belgium, Luxembourg, Slovakia, Norway, Switzerland, Turkey, Republic of North Macedonia, Iceland, Montenegro