Success Story: Enabling HPC Usage for Expensive ML Tasks on Manufacturing Environments
NCC presenting the success story



Turkish National e-Science e-Infrastructure (TRUBA), operating under Turkish Academic Network and Information Center (TUBITAK ULAKBIM) is the coordinator of NCC Turkey. Middle East Technical University (METU), Sabancı University (SU), and Istanbul Technical University National Center for High-Performance Computing (UHeM) are the third parties of the NCC.
While METU is a public university based in Ankara, SU is a privately-funded university in Istanbul. ITU UHeM, also based in Istanbul, provides supercomputing and data storage services to academic and industrial users. Our competencies include High-Performance Computing (HPC), High-Performance Data Analytics (HPDA), Artificial Intelligence (AI), CUDA, Materials Science, Computational Fluid Dynamics (CFD), and several other fields. The particular third-party presenting this success story is Sabancı University.
Technical/scientific Challenge:
Erste is working on two international manufacturing projects. They require Anomaly Detection and Predictive Maintenance models trained on a huge amount of data. The company is highly fluent in front- and back-end development; the R&D team was developing prediction and classification algorithms to reduce the maintenance cost and downtime of the press machines used in production. However, in their use-case, the data can stream from up to 10 production lines, each having 3-10 machines, and each machine is equipped with sensors producing tens of data points in every milli-second. Having expertise on streaming data processing, Erste did not have any HPC skills or know-how on HPC clusters, SLURM, etc. This is why they have applied to the center.
Business impact:
Considering the size of the manufacturing companies and the data that is produced/gathered from the machines, the tool will improve the applicability of the ML on Erste’s solution. For instance, training a medium-sized ML model on the server containing the streaming DB and answering the queries takes around 1 hour (on 8 cores) while no queries are being executed on it. With TRUBA’s high-end CPUs, the time reduces to around 30 minutes (on 8 cores) and with a single GPU, the training takes less than 10 minutes. Overall, the tool developed in this use-case allows Erste to keep the scarce on-site computational resources dedicated to their end-to-end Predictive Maintenance tool, basic data processing, e.g., rule-based anomaly detection on streaming data and data queries and leverage external HPC clusters.
Industrial Organisations Involved:

Erste Software is an SME founded in 2017 in Ankara, Turkey. Its focus is smart environments, and its main expertise is on Internet of Things and Big Data solutions. Despite being a young SME, Erste employs an experienced R&D team that has been involved in several EU-funded projects mainly leveraging industrial IoT technologies such as Optimum, Pianism, I2Panema, Machinaide, and Gamma. Overall, the company has three main products (1) IoTWare, an engineering tool suite for enhanced smart environments (2) MobiVisor, a secure mobile platform management tool, and (3) Detangle, an innovative feature-based effort and quality analysis software.
Solution:
As ML models get larger, the amount of time and resources needed for training that doesn’t reduce the performance gets larger as well. Using an HPC cluster answers Erste’s needs in terms of computation resources. In this way, the end-to-end predictive maintenance tool they have can work on-site as is without consuming the critical server resources while offloading heavy ML tasks to leverage an external cluster and being able to perform them faster than regular servers. This being said, there was no such solution enabling HPC usage at the time when we started the use case.
With the center’s consultancy and guidance, a solution that enables HPC usage is designed. Given a set of future tasks, the tool can automatically handle data movement, training, downloading models and deploying them back to the on-site server. To implement it an Erste engineer has learned to use SLURM, which is a cluster management and job scheduling system providing an interface for executing and monitoring tasks, and managing the contention for resources. At the end of the use case, Erste completed a proof-of-concept implementation of this module for their ML-based predictive-maintenance tool.
Benefits:
- A state-of-the-art tool has been developed to offload streaming-data computations to an HPC cluster has been developed.
- The tool allows on-site computational resources which are usually scarce to be dedicated for the actual task.
Significant performance improvement has been obtained in ML training.
SUCCESS STORY # HIGHLIGHTS:
- Keywords: Offloading ML, manufacturing, streaming data.
- Industry sector: Manufacturing & engineering.
- Technology: HPC, AI.
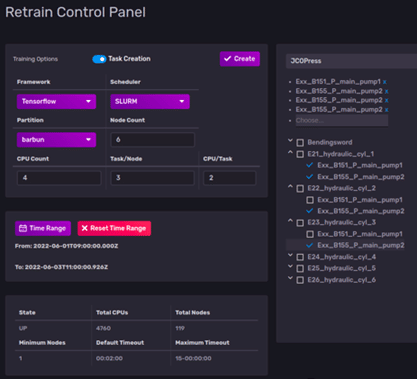
Contact:
Kamer Kaya, Sabancı University, Computer Science and Engineering, E-mail:kaya@sabanciuniv.edu.
This project has received funding from the European High-Performance Computing Joint Undertaking (JU) under grant agreement No 951732. The JU receives support from the European Union’s Horizon 2020 research and innovation program and Germany, Bulgaria, Austria, Croatia, Cyprus, the Czech Republic, Denmark, Estonia, Finland, Greece, Hungary, Ireland, Italy, Lithuania, Latvia, Poland, Portugal, Romania, Slovenia, Spain, Sweden, the United Kingdom, France, the Netherlands, Belgium, Luxembourg, Slovakia, Norway, Switzerland, Turkey, Republic of North Macedonia, Iceland, Montenegro